
Avoir un site web sans l’optimiser pour les fondamentaux SEO, c’est comme fermer son magasin pour empêcher de vendre. Le fichier robots.txt joue un rôle très important dans l’optimisation de la technique SEO. Ceci étant, il doit être créé et optimisé.
Si vous voulez comprendre l’utilité du fichier robots.txt ainsi que sa création sur un site web, cet article vous guidera étape par étape.
Qu’est-ce que le fichier robots.txt ?
Selon Google, “un fichier robots.txt indique aux robots d’exploration d’un moteur de recherche les URL auxquelles il peut accéder sur votre site. » C’est ce qu’indique le géant américain sur son site d’aide aux webmasters.
Un fichier robots.txt est tout simplement un document texte qui empêche les robots d’explorer tous les dossiers et pages de votre site web.
En effet, quand les robots d’un moteur de recherche veulent explorer un site internet, ils consultent en premier lieu le fichier robots.txt. C’est ce fichier qui leur donne les différentes directives à suivre sur le site, les dossiers à découvrir et ceux à ne pas découvrir.
Mais attention, notons toutes fois que certains robots ne respectent pas les directives du protocole robots.txt. Ces robots sont des robots malveillants envoyés par des pirates pour aspirer votre site web.
D’ailleurs, si vous vous rendez compte que votre site web subit trop de demandes et de surcharge, vous pouvez vérifier s’il s’agit vraiment des robots de Google et non des robots malveillants. Ce guide vous permettra de le faire étape par étape.
Il est à noter aussi que le protocole d’exclusion des robots est un fichier public, n’importe quelle personne peut accéder. En conséquence, ne mettez jamais des données sensibles dans un fichier robots.txt. Par exemple, voici ci-dessous le contenu du fichier de ce site.
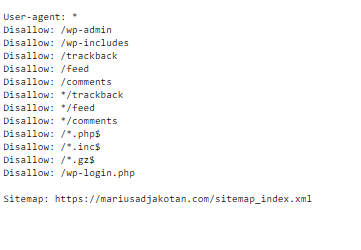
Enfin, le troisième point à partager avec vous. Le protocole d’exclusion des robots ne sert pas à empêcher l’indexation d’une page web. Par exemple, si vous bloquez accès à une page ou à un dossier avec robots.txt et qu’un site internet externe fait référence à cette page par un lien hypertexte, la page web sera indexée par Google.
Ainsi, pour empêcher l’indexation d’une page, utilisez toujours la valeur « noindex » dans la balise <head>.
<meta name="robots" content="noindex" />Le fichier robots.txt : est-il important pour votre site web ?
Beaucoup de webmasters se posent la question si le protocole robots.txt est important. En effet, il n’est pas indispensable pour l’exploration de votre site internet. Lorsque les bots des moteurs de recherche demandent à consulter le fichier robots.txt et que ce dernier n’existe pas, alors ils parcourent le site web entier.
Par contre, ce fichier peut devenir indispensable pour le référencement naturel de votre site si vous disposez d’un site volumineux, plus d’un million de pages web uniques. Ou bien, assez de vos pages web sont déclarées Détectée, actuellement non indexée dans la Search Console de Google.
En effet, le web est vaste. Google a déjà enregistré plus de 1000 milliards de pages web dans son index. (Source : WebRankInfo)
Pour cela, le géant de la search prévoit une quantité de ressources technique à utiliser pour crawler chaque site web. On appelle cette quantité de ressource le budget de crawl ou crawl budget. Si le budget de crawl est élevé, alors Google peut explorer assez de pages web. Par contre, s’il est faible, Google peut explorer peu de pages web de votre site.
Si vous laissez Google explorer toutes les pages web de votre site, même si certaines sont peut-être inutiles pour les robots, votre crawl budget peut diminuer. Si les performances de votre serveur ne sont pas bonnes ou bien il y a fréquemment des problèmes réseaux lors des demandes de téléchargement des ressources du site, votre crawl budget peut réduire aussi.
C’est pourquoi il est conseillé d’avoir un fichier robots.txt qui bloque l’accès aux ressources inutiles du site. D’autre part, il est conseillé de prendre également des serveurs de bonne performance.
Si vous voulez explorer davantage le sujet du crawl budget, je vous conseille de lire cet article de WebRankInfo.
Comment le fichier robots.txt est-il interprété par les robots ?
Pour comprendre comment le fichier robots.txt est interprété par les robots d’explorations, commençons par comprendre la syntaxe du fichier robots.txt. Pour cela, il suffit de comprendre les différentes directives. Voici les directives que vous devez comprendre :
- User-agent : c’est une directive qui indique le nom du robot ciblé.
- Disallow : c’est la directive qui permet d’indiquer la ressource que vous souhaitez bloquer l’accès
- Allow : elle est facultative mais elle est utilisée pour indiquer explicitement les ressources auxquelles le robot a accès.
- Sitemap : c’est une directive qui permet d’indiquer le fichier sitemap du site web. Elle est aussi optionnelle.
Par exemple, prenons l’exemple de ce fichier robots.txt ci-dessous.
User-agent: Googlebot
Disallow: /secure/
User-agent: *
Allow: /
Sitemap : https://domaine.com/sitemap.xmlCe fichier indiqué ci-dessus indique au robot Googlebot de ne pas accéder au dossier https://exemple.com/secure/. À part cela, il peut accéder à tous les autres dossiers. Par contre, tous les autres robots d’explorations peuvent accéder à tous les dossiers du site. Enfin, on indique aux robots d’exploration le lien du sitemap.
Retenez que lorsqu’un robot d’exploration consulte un fichier robots.txt, il regarde en première position si son nom a été indiqué explicitement. Si oui, il se conforme aux directives indiquées. Dans le cas contraire, il choisit ce qui s’applique à tout le monde et suit ces règles.
Comment créer un fichier robots.txt ?
Pour créer un fichier robots.txt, il suffit de prendre votre éditeur de texte préféré et de commencer par donner les directives que vous souhaitez. Cela peut être Sublime Text, Notepad++ ou encore notre simple Bloc-Notes de Windows.
Après avoir créé votre protocole d’exclusion, téléchargez-le sur votre serveur en ligne. Pour cela, connectez-vous au serveur à partir d’un client FTP, par exemple FileZilla. Si un fichier robots.txt existe déjà sur votre site, il suffit de le supprimer et de télécharger votre nouveau fichier sur le serveur.
Un point très important à ne pas oublier : assurez-vous de télécharger le fichier robots.txt à la racine du serveur.
Comment tester votre fichier robots.txt ?
Une fois votre fichier robots.txt téléchargé sur le serveur, le dernier point est de le tester afin de vérifier s’il y a des erreurs dans votre document.
Pour cela il suffit d’utiliser ce site de Google pour effectuer le test de votre protocole robots.txt.

En conclusion
Le fichier robots.txt est un fichier qui empêche l’exploration d’une ressource web. Il peut être indispensable pour votre site web, surtout du côté du référencement naturel.
Sachez que c’est un fichier public et qu’il ne faut indiquer aucunes données sensibles. Par ailleurs, il ne s’agit pas d’un fichier qui bloque l’indexation d’une page web. Si vous désirez bloquer l’indexation d’une page web, utilisez la balise noindex.
Questions fréquentes sur le fichier robots.txt ?
Le fichier robots.txt est un document texte placé à la racine d’un site web qui indique aux robots des moteurs de recherche quelles parties du site peuvent être explorées et indexées.
Vous pouvez créer un fichier robots.txt en utilisant un éditeur de texte simple comme Bloc-Notes sous Windows ou Notepad++ en respectant la syntaxe spécifique.
Vous pouvez utiliser des outils en ligne comme l’outil d’inspection de l’URL de Google pour vérifier si votre protocole robots.txt bloque ou permet l’accès aux pages souhaitées. Par ailleurs, vous pouvez aussi vous servir de l’outil de test de fichier robots.txt pour identifier les erreurs commises.
En absence d’un protocole de directives, les robots des moteurs de recherche exploreront et indexeront (pas obligatoire) l’ensemble de votre site, sauf s’il y a des balises meta noindex ou des en-têtes HTTP spécifiques.
Oui, vous pouvez utiliser robots.txt pour bloquer l’accès aux pages sensibles. Cependant, il ne garantit pas la confidentialité absolue. La meilleure pratique serait de mettre un mot de passe sur ces pages sensibles ou d’interdire l’accès à cette page dans votre fichier .htacess.
Oui, des erreurs dans le document robots.txt, telles que le blocage accidentel de pages importantes, peuvent entraîner une baisse de classement dans les résultats de recherche.
Vous pouvez autoriser tous les robots en utilisant la directive « User-agent: * ». Vous pouvez également spécifier des règles d’accès pour des robots spécifiques.
Non, le robots.txt est destiné à contrôler l’accès des robots des moteurs de recherche, il ne bloque pas les publicités en ligne.
La plupart des moteurs de recherche, y compris Google, respectent robots.txt. Cependant, il est possible que certains robots l’ignorent, il ne garantit donc pas la confidentialité complète de votre site.
Par défaut, le protocole robots.txt d’un site WordPress est créé automatiquement par le plugin Yoast SEO. Mais si vous voulez, vous pouvez le changer pour l’optimiser.
💡À lire aussi : Qu’est-ce que les données structurées en SEO ? (Tutoriel complet)






